Overview
A client operating critical workloads on on-premises infrastructure needed a high-availability disaster recovery strategy that was scalable, cost-effective, and reliable. The solution had to fit within a tight budget while meeting compliance requirements — and it had to be delivered in two weeks.
The pay-as-you-go model of AWS Elastic Disaster Recovery made it possible to give the client enterprise-grade resilience without the capital expense of a traditional secondary data center.
The Challenge
The stakes were high on every dimension. The budget was constrained, the compliance audits were imminent, and the two-week delivery window left no room for architectural pivots. The client needed a solution that could be stood up quickly, validated against compliance frameworks, and trusted to perform under real failure conditions.
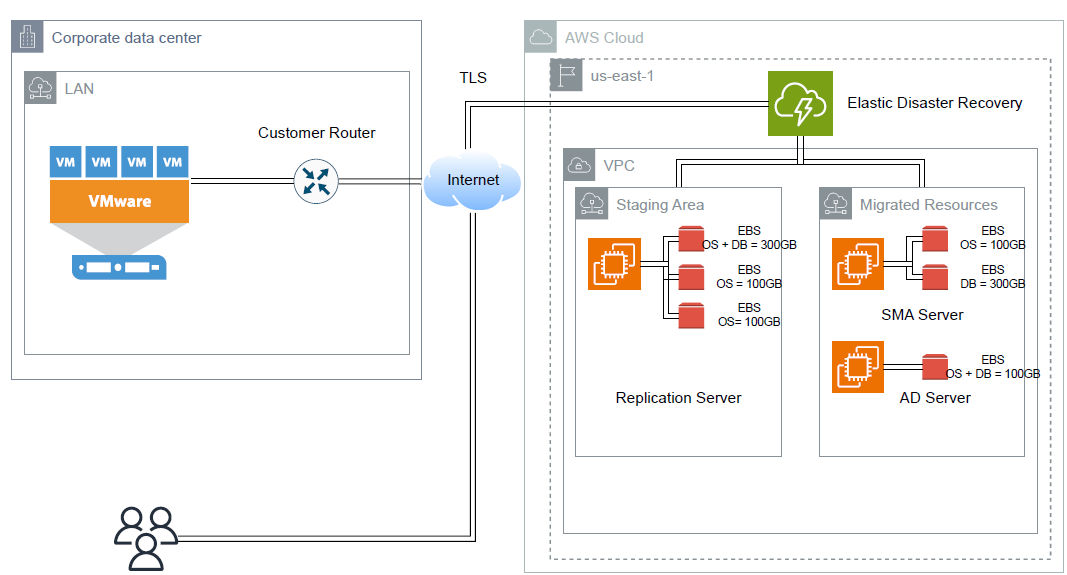
Architecture
The solution was built on AWS Elastic Disaster Recovery (AWS DRS), with the replication agent deployed across the client’s VMware on-premises environment. Block-level replication established continuous data synchronization to AWS, with an RPO measured in minutes rather than hours.
AWS CloudFormation managed the infrastructure-as-code layer, ensuring the recovery environment was reproducible and auditable. Python automation handled agent deployment orchestration and health monitoring. Security controls were implemented across the replication pipeline and recovery environment to satisfy compliance audit requirements.
The architecture established a clear recovery path: on-premises VMware workloads replicate continuously to AWS EC2, with failover procedures tested and documented before go-live.
Outcome
The client achieved a resilient operation with downtime reduced from hours or days to minutes. The compliance audits were passed successfully. The pay-as-you-go model meant the client only incurs full compute costs during an actual failover event, keeping ongoing DR costs minimal while maintaining enterprise-grade recovery capability.